SEO is one of the best — if not the best — sources of organic traffic your business can get.
In fact, around 84,898 Google searches are made every second, bringing plenty of opportunities for businesses like yours to get organic traffic on their website.
This is why almost every business wants to tackle SEO. And the reason why you’re probably investing tons of time creating blog posts, doing keyword research, and building links (or buying links).
Unfortunately, this opens the door for a lot of potential SEO mistakes that non-technical people may be falling into without even noticing.
Because, after all, SEO requires some technical knowledge.
But don’t worry, I’m not here to teach you HTML. Instead, we’re going to focus on the most common technical SEO mistakes made by beginners and how to fix them with ease.
So if reading this alleviates you, keep scrolling.
How to identify technical SEO issues
The best way to identify problems is by conducting an SEO audit. An SEO audit allows you to get into the deepest side of your site and find those little tiny errors that may be hindering your Google rankings.
And in our new normal of remote virtual workers spending more time online, this is something you can no longer afford to miss out on.
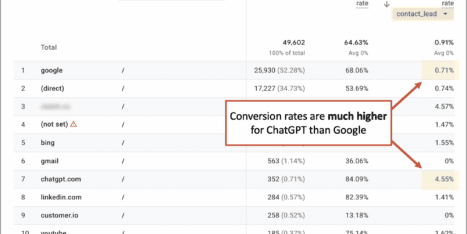
To do this, you can simply use an SEO tool like Ubersuggest, put your site URL, and get a report of errors and warnings that are hurting your SEO potential.
It should look similar to this:
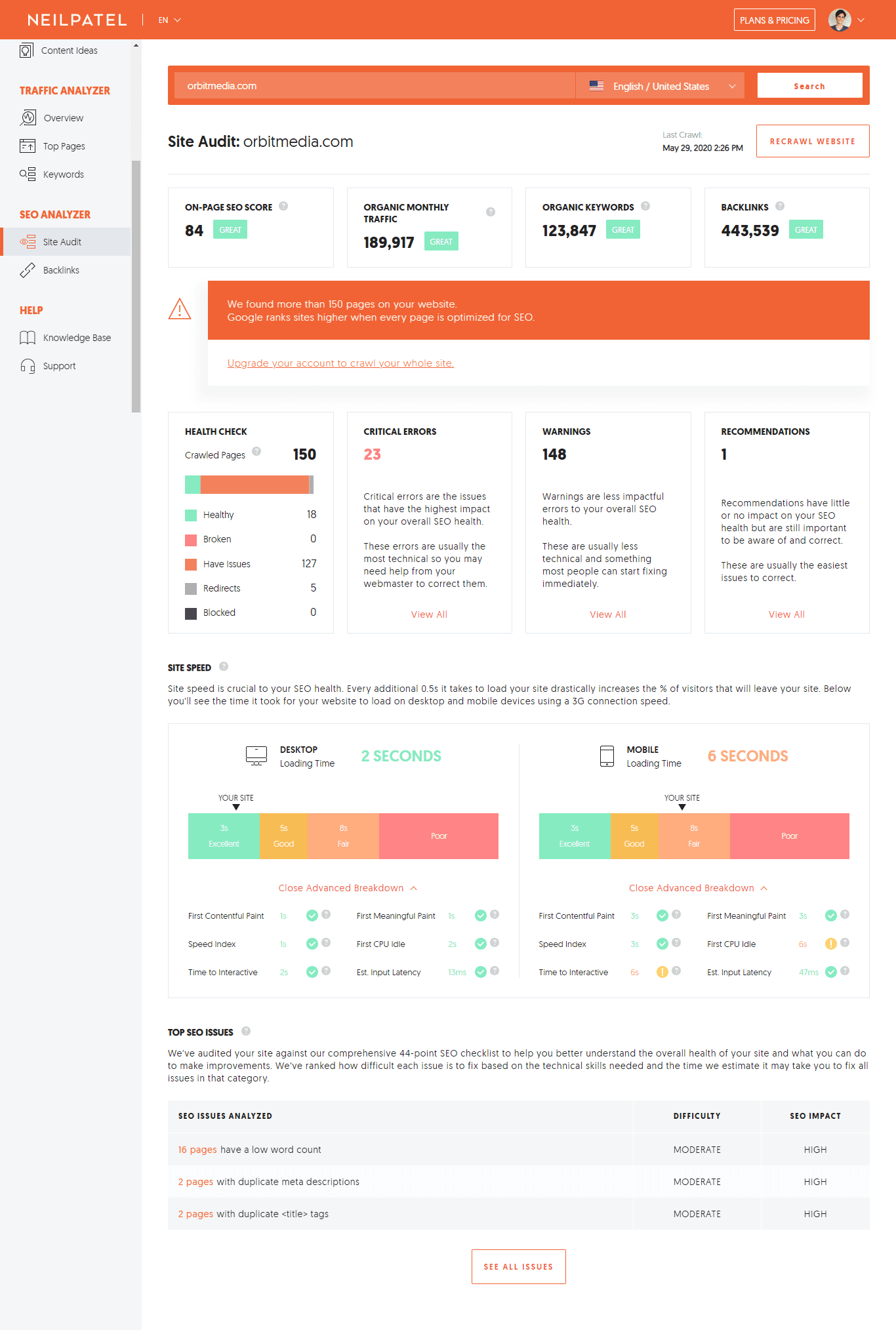
SOURCE: OrbitMedia’s site audit on Ubersuggest
Chances are that you’ve got many website issues that are keeping you from ranking higher, and thus, you need to address these problems as soon as possible.
An automatic SEO audit is great and all. But if you want a more sophisticated SEO audit, using software won’t be enough. You’ll need to check things manually.
That’s why we’re going to go through the most common SEO mistakes, and the easiest ways to fix them.
I hope you got enough sleep last night and you’re ready to roll because this post is packed with actionable information you can start using right away.
Now that you know how to ID technical SEO issues, let’s dive into those (simple) SEO mistakes that are killing your rankings (and how to avoid them).
Mistake #1: Your sitemap and robots.txt aren’t properly configured
Your sitemap.xml and robot.txt files are essential so Google can crawl your website and index your pages.
These files are responsible for telling Google what and how to crawl your website and make it easy for crawlers to understand its structure.
When these files are misplaced and not well-configured, you’ll get into crawl problems. And remember, Google can’t index and rank your pages if it can’t crawl it.
To make sure that you’re not having any issues with this, first:
1) Make sure that your robot.txt isn’t blocking your site.
The robots.txt file tells the crawl robots where they’re allowed to go to and where they shouldn’t go.
Head over your robots.txt by going to “www.yoursite.com/robots.txt” and check if it isn’t preventing the crawlers to look at your pages.
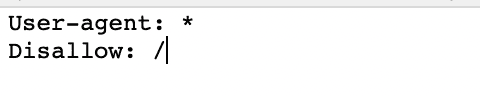
If it shows a “/” after “disallow:” like the image above, then it is blocking your site from being crawled and you need to remove the slash.
If your site is a bit more complicated than that, you’ll need to manage the folders you’re allowing and disallowing. Make sure you’re not unintentionally blocking valuable pages from being crawled.
2) Manage your “crawl budget”
According to Google, crawl robots have a “crawl rate limit” for each site. So it is a good practice to manage your “crawl budget” based on the “crawl rate limit” that Google puts on your site.
If your website has a lot of low-quality pages and folders that you don’t need to index, then it is worth blocking those pages from being crawled, so you can optimize the “crawlability” of your website and see more rankings faster.
Here’s a simple 4-step process to view and analyze all the pages on your site for effective “crawl budget” management.
3) Verify that your sitemap.xml is submitted
The XML sitemap shows the most valuable pages of your website and helps crawlers to better understand its link structure.
If your website is missing a sitemap, these Google’s crawl robots will have a hard time checking your site, thus affecting your SEO performance.
To make sure everything is right, use Google search console and look for the sitemap:
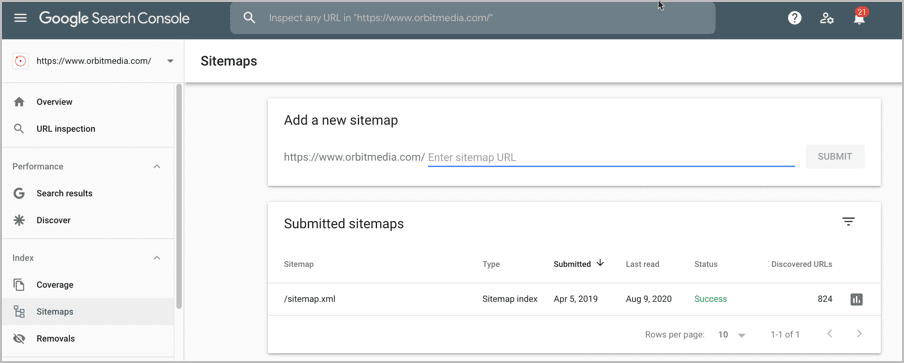
Check if:
- The sitemap is located in the root directory.
- The XML sitemap is listed in the robots.txt file.
- The most valuable pages are included in the sitemap.
- The sitemap structure is optimized for indexing.
As a final note. If you’re using WordPress your robots.txt file will probably look like this:

This just means it is blocking access to your WordPress folders and allowing the content that’s coming from it.
Mistake #2: Link structure issues
Having a healthy link structure on your website improves both searchability and user experience.
But it’s a common mistake to change a page’s permalink and forget about updating the rest of the pages that are linking to that specific page.
This won’t only bring a 404 error to your user’s screen but also keep your page from being found by crawl robots.
To prevent this issue from happening, you need to keep an eye on your link structure. Following these steps:
1) Search for both internal and external broken links in your website
Having broken links in your site will affect your SEO performance negatively, that’s for sure.
And this isn’t something 100% under your control as a website you’re linking to can potentially change its URL without letting you know. Which… can give you this headache.
To avoid this, make an audit and spot every broken link and replace them with something more valuable to the user.
You can either use Google search console, Yoast, or a tool like Broken Link Check to find broken links.
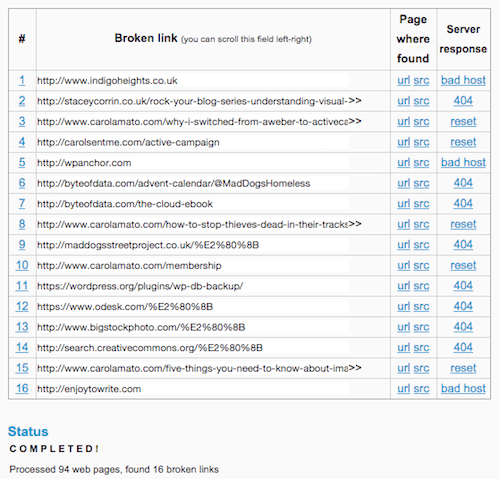
From here, you’ll be able to fix this issue relatively quickly and easily.
2) Make sure your site’s crawl depth doesn’t surpass three clicks
Crawl depth refers to the number of clicks it takes to get to a certain page from the homepage.
As a standard, very few pages should surpass the 3 clicks threshold.
This doesn’t mean you should link everything right from the homepage, as that would hurt user experience and, overall, your customer relationship.
So, in order to leverage your link structure, take advantage of category sections, and organize your content in a way that’s easy for the user to navigate and reach the majority of your pages.
Just make sure you’re not leaving any orphan page behind.
3) Find orphan pages in your website
Orphan pages aren’t internally linked from anywhere.
Google sees orphan pages as something not worth indexing. So if you’ve been publishing content without taking care of internal linking, you probably have some orphan pages around that you need to attend to.
You can use an SEO tool like Ryte to spot orphan pages. And from there, start adding links to complement your website structure, to make it more polished and attractive for Google.
Mistake #3: Duplicate content
Duplicate content is a great source of risk for your rankings.
And with good reason, since Google needs to penalize duplicate content for plagiarism issues and to encourage good user experience.
It can cause you to compete with yourself and confuse Google in the process.
Common sources of duplicate content include printable pages, Http versions of your site, author pages, and even two pages sharing the same H1 tags, title tags, and meta descriptions.
Even when a product page can be found in different categories, it may show two different URLs, and Google can interpret that as duplicate content.
To address this issue, ask yourself:
- Do the URLs have parameters or tracking codes?
- Do completely different URLs have identical content? This often happens with product pages as I said above.
- Do different pages have the same meta tags (meta title, meta description)? If so, learn to write SEO-friendly meta tags for your content, and use them to differentiate your content in the SERP.
- Copy a section of the content in quotes, and enter it in the Google Search. Is the content appearing elsewhere else in your domain (or even subdomains)?
- Have you deleted any duplicate content already? If so, you probably need to submit a request to Google to remove the content.
- Do you have printable versions of specific pages?
When you spot duplicate content, you can either delete old content, tag the most important version as canonical (with “rel=canonical”), or use 301 redirect to, for example, redirect the Http version of a page to its https version.
Mistake #4: “Noindex” tag problem
Meta robot tags like “Nofollow” are responsible for telling Google crawlers whether a link is worth considering or not.
And it hurts your ranking when you’re accidentally leaving Nofollow tags over your website, hurting your site’s “indexability” in the process.
To solve this, identify every page with the “Noindex, Nofollow” tag.
And then, check to make sure you’re not blocking any valuable content from being ranked.
If you are, remove them. And replace for the default “all” or “index, follow”.
If there are some pages that need the Noindex command then leave them as they are (like category pages, shopping carts, thank you pages, etc…).
However, take notice that too much use of “noindex” can directly reduce the overall crawl rate of your site.
Mistake #5: Your site isn’t fast enough
Site speed is one of the top Google’s ranking factors out there.
And the reason for it is quite evident. As the slower your site, the more likely your visitors are to bounce back to the SERP and click on a better, faster page — and Google penalizes that.
So having a fast loading website is now a requirement for SEO.
To keep this on-check, follow this simple procedure:
1) Run a page speed test
Google has its own tool to measure site speed, letting you know how optimized your site is.
Alternatively, you can use something like Pingdom or GTmetrix if you want extra input.
These tools will tell you what are the biggest issues with your pages, and guide you in the optimization process by throwing out a report like this one:
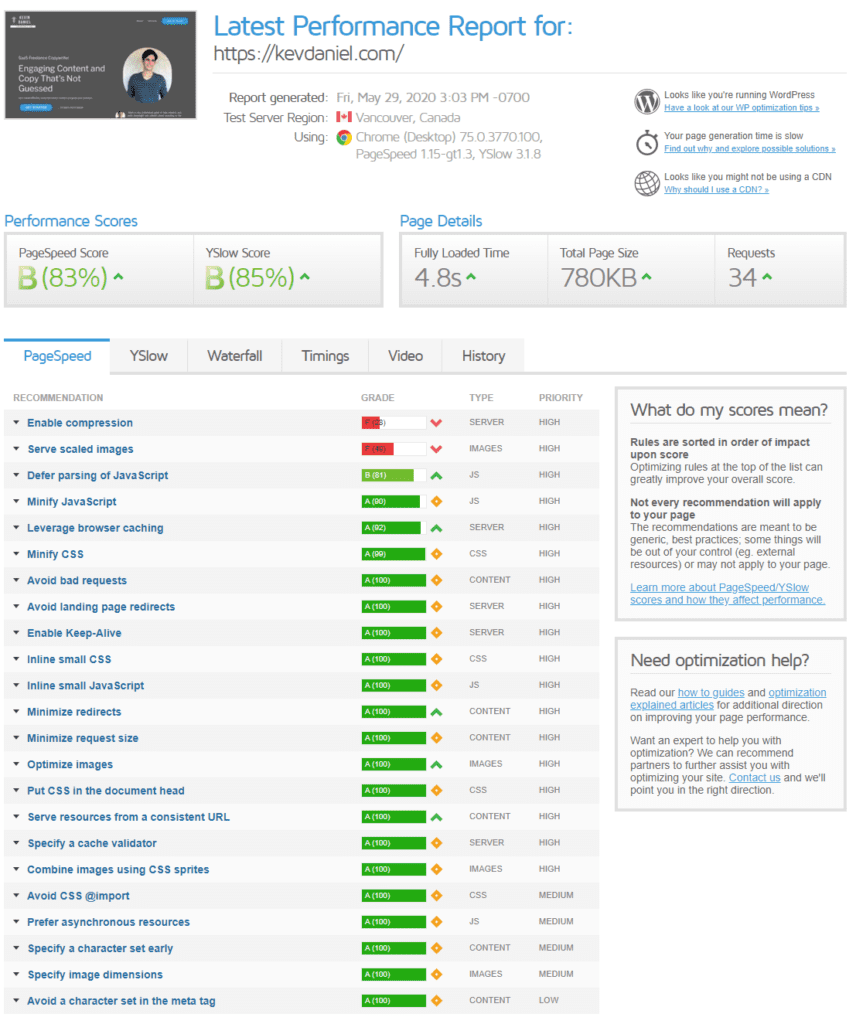
As illustrated in this screenshot, it will show your site’s performance and the factors that are keeping it from getting faster (like image compression and scaling in this specific example).
2) Analyze the report and optimize as much as you can
Next, you need to start shaping up your site to make it faster.
3 seconds or less is the standard load time. So check the report to see what the major factors are affecting your site load speed and fix them.
Some key practices to keep your load speed optimized include:
- Optimizing image size (among other image factors affecting SEO, especially for infographics)
- Getting a fast WordPress theme
- Replacing plugins that are taking too much time to load
- Compressing JavaScript, HTML, and CSS files, and Gzip
- Leveraging caching to make your site more efficient
A plugin like W3 Total Cache can help you do at least half of this optimizing work if you use the right caching settings. But you should still keep the habit of tracking your site performance to avoid messy situations.
Mistake #6: Your website isn’t responsive
Since 2017, Google has been taking mobile searches into consideration, taking responsive design as a ranking factor.
This means your website needs to be optimized for mobile. Otherwise, Google assumes your website is low-quality.
EDIT: This test has been discontinued by Google. It looked like this:
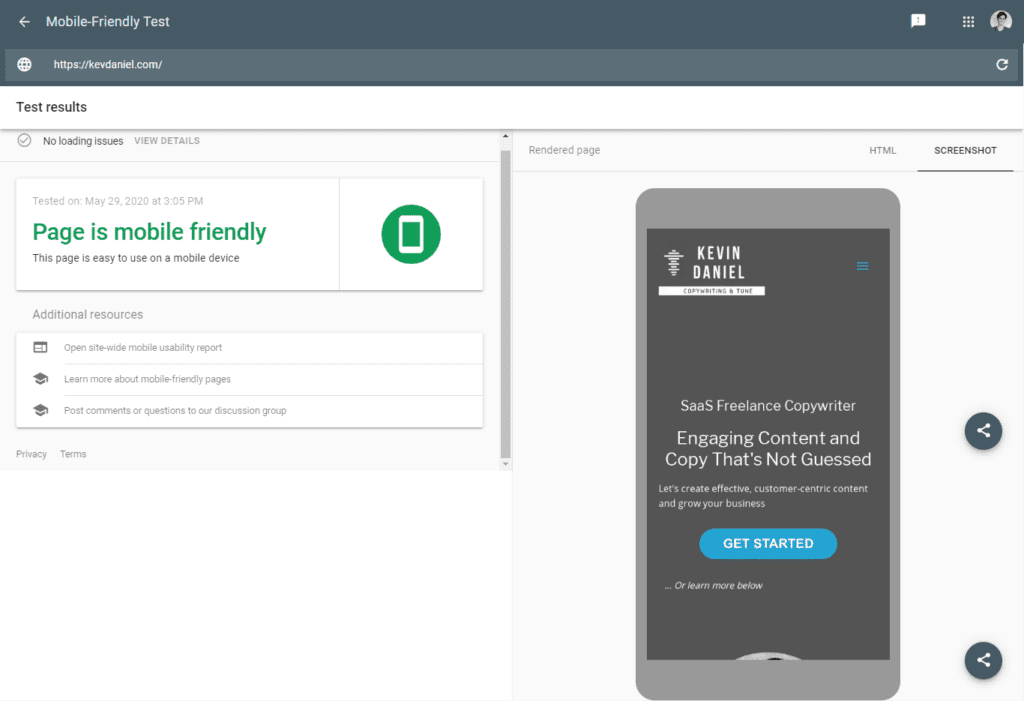
Who better than Google to know if your website is mobile-friendly enough for SEO?
Here are some errors you can get from the report:
- Touch elements are too close and you need to re-define the layout.
- Fonts are too small and you need to go back to your CSS file and re-adjust.
- In the worst scenario, you don’t have the meta viewport tag. If this is the case, you’ll need to include this line in your page, so your site can respond to the user’s device:
<meta name=”viewport” content=”width=device-width, initial-scale=1″>
You can also navigate your website from your own phone and check if there are some malformed elements and images with awkward resolutions.
Mistake #7: Too many 301 redirect chains
301 redirect chains aren’t good for SEO and you lose link equity for every step in the chain.
Redirects are great to eliminate duplicate content issues and to remove old content from the indexing, so you’ll find yourself using redirects a lot.
But be aware of not generating any chains, since Google suggests not to follow redirect chains with multiple steps, and they’re very likely to rate your target page lower for this.
To fix this, edit your redirects so instead of following this pattern:
URL 1 —-> URL 2 —> Target URL
It follows something like this:
URL 1 —-> Target URL
URL 2 —-> Target URL
You can use a software like Screaming Frog Spider SEO to spot your redirect chains and fix them right off the bat.
Avoid costly mistakes using this checklist
Now, let’s wrap up everything into a checklist.
Use this checklist to ensure that you’ve got everything right and optimized in your website:
✔️ Sitemap XML and Robots.txt properly configured. Check these files and make sure that they’re not preventing your website from being successfully crawled.
✔️ Broken links fixed. Clean your website replacing every broken link for a better, more valuable one.
✔️ Optimized crawl depth. Organize your content categories and try to keep crawl depth under 3 clicks
✔️ Reduced orphan pages. Find every orphan page, and if they’re valuable, include them in your link structure.
✔️ Duplicate content issues fixed. Look for every threatening duplicate content and take appropriate measures.
✔️ No misplaced “Noindex” tags. Make sure you’re not accidentally telling Google to not index some of your valuable pages.
✔️ Load speed optimized. Check your load speed, and look for ways to optimize even further.
✔️ Responsive, mobile-friendly website. Test and navigate your website, and look for ways to improve user experience for mobile users.
✔️ 301 redirect issues fixed. Break as many unnecessary redirect chains as you can.
Technical SEO doesn’t have to be a struggle
At first, technical SEO can be overwhelming.
But as you’ve seen, it doesn’t have to be as daunting as it seems if you start to understand the reason behind its quirks (you may even start to enjoy it).
If you avoid making these mistakes while applying the best practices we covered, your website will:
- Become easy to find and crawl for Google
- Get plenty of indexable content that Google will rank
- Be able to reach mobile users and improve your brand awareness
- Reduce its bounce rate as a result of fast loading speed and optimal appealing user experience
- Improve its organic traffic numbers over time (as long as you keep creating high-quality, SEO optimized content)
Truth is:
SEO is a marathon, not a sprint.
Because it only pays-off for the long-term. And if you commit to keeping your site healthy, you’ll eventually see the worth behind all the hustle.
So keep working and you’ll soon reap the positive benefits of proper SEO.