“Nofollow” links are the most controversial topic in all of SEO. Very few SEO professionals agree on it: Even the ones that have been immersed in the topic for decades. If you read this post to its conclusion, you’ll understand why. And, you might just form a strong opinion of your own.
Plenty of smart people disagree. But, in a fact check of Google ranking factors, any single source citation is a disaster when it comes to “nofollow.”
What are “nofollow” links?
“Nofollow” is an HTML attribute that can be used with any link on the web.
Here’s what the code looks like:
<a rel="nofollow" href="https://www.website.com">This attribute exists solely for SEO reasons.
Where did “nofollow” come from?
“Nofollow” was introduced by Google in 2005 to “fight comment spam.” They made the following claim in black and white:
“When Google sees the attribute (rel=”nofollow”) on hyperlinks, those links won’t get any credit when we rank Web sites in our search results.” — Google, 2005.
No value. Nothing. And, they go on to explain:
“This isn’t a negative vote for the site where the comment was posted; it’s just a way to make sure that spammers get no benefit from abusing public areas…” — Google, 2005.
I notice two things.
- They’re expressing a “devaluation” and not a “penalty.” So, if you’re asking: Can “nofollow” links hurt? Google bluntly told us “no.” The value may become zero but it does not become negative.
- Notice the laser-focus on “public areas,” “spammers,” and “comments?” Google wasn’t thinking about much except user-generated portions of a website.
Man, that made it so clear and simple, didn’t it? There were three problems.
- Google changes.
- The web changes.
- Google’s advice has a history of not panning out in testing.
Most SEO advice that I hear nowadays about “nofollow” was formed only by what you’ve read so far. Huge mistake. Soon, everything would change.
How did “nofollow” change?
The role of “nofollow” expanded rapidly. A few months later, Google’s Matt Cutts began recommending it for any paid advertisement and later still, for “any link that is not editorial.”
Did you notice, above, that there’s also no penalty for the link-er to use the “nofollow” attribute?
Can you guess what happened?
If “nofollow” can protect your own site from being associated with bad websites, a website owner has nothing to lose and everything to gain by just setting every outbound link to “nofollow,” right?
It took no time before every last link on Wikipedia tested that theory. They went “nofollow” across their entire website. By 2006, certain SEO voices were explaining how we all might steal away the last bit of authoritative links from Wikipedia that they overlooked.
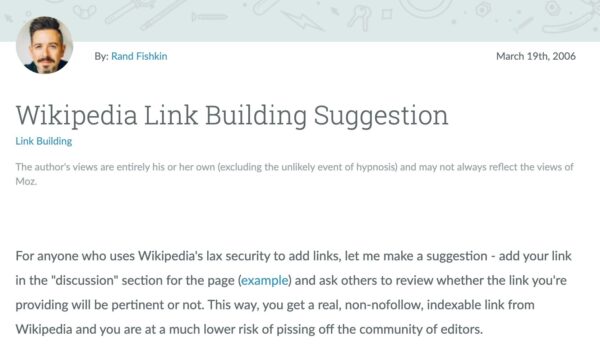
To Rand’s credit, 2006 was what we now know to be “Pre-White Hat” SEO. Everybody was doing it.
We’re talking tens of millions of “nofollow” links. It didn’t hurt Wikipedia. In fact, greater than 50 percent of all Google search results contain Wikipedia in the top 10. Wikipedia is the greatest success story in the history of SEO so far.
“Nofollow”-ing everything suggested that Wikipedia will never get hit with a Google penalty for bad neighborhood links, paid link schemes, or anything else that, you know, would have required them to police the quality of their own website.
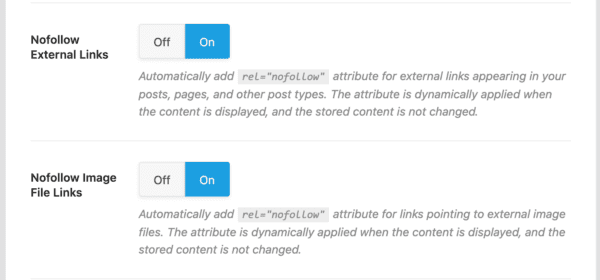
And you know who else likes to benefit from laziness? Everybody. Have you ever configured a website to do this?
Meanwhile, Google couldn’t get enough “nofollow”-ing. They were hooked. By 2013, official advice had evolved into:
- Widgets. (Sure.)
- Infographics. (Why not?)
- Product reviews. (Oh yeah.)
Talk about scope creep. Google wasn’t going to rest until every link on the entire web had a “nofollow”.
As this went on, the lingo around “nofollow”‘s impact began changing. Matt Cutts began to lawyer his words a bit. Somewhere along the way, Google’s stance became:
“In general, we don’t follow them.” -Matt Cutts, 2013
Dozens of studies were emerging that indicated that Google really was crediting “nofollow” links with value. Here’s a quick selection of these experiments and their results.
- TekNick’s 288 percent growth from 88 low-end “nofollow” links.
- Fractl’s 271 percent growth from a “nofollow” on BuzzFeed.
- SurveyMonkey’s content getting indexed in mass via “nofollow” links.
For most, the simplest and most effective “nofollow” test was a Wikipedia link. Especially from one of their non-English subdomains, with much less editorial oversight and greater starvation for good content and source citations.
Point a “nofollow” at a site with no prior links and a low (or no)-competition word in its copy. For that Google search, it should skyrocket. Indexing begins (or accelerates). For a very long time, this has been reliable.
Did we reach the breaking point?
In 2019, Google was forced to admit what we knew for nearly a decade: To a search engine, “nofollow” is not a useful signal. It hasn’t been for a long time. Not when the common wisdom is to just apply it everywhere for some potential upside and no downside.
We’ve come full circle with two new link attributes. They’re grasping at what might have been.
rel=”ugc“ now exists for user-generated content (the exact role that “nofollow” was created to serve).
rel=”sponsored” for paid links (repeating the first bastardization of “nofollow” that we covered above).
At Pubcon 2019, Google’s Gary Illyes volunteered a fact that was already known by anybody with access to Ahrefs or Moz: More than half of the links on the web are now marked “nofollow.”
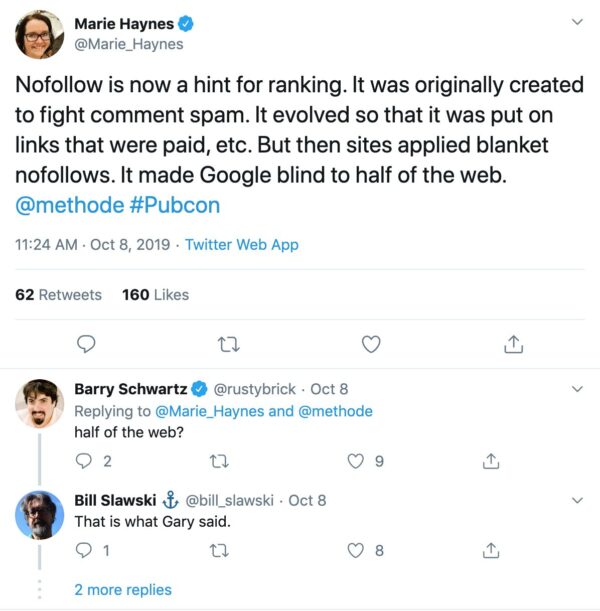
We already knew that the percentage of “nofollow” to regular links was ridiculous. That was a data-driven fact. But this was the first time that I’d seen Google directly admit that they weren’t actually ignoring all that juicy data.
Plugins like WPEL for WordPress now make it easy for everybody to Wikipedia-ify all their outbound links. And why wouldn’t they? Core SEO suites (like Rank Math) have that feature baked in now, too. Everybody’s doing it.
That’s why it came as no surprise to hear Google officially refer to “nofollow” as what I’m fairly certain that it already has been for a very long time. A minor “hint” that gets considered alongside hundreds of other inputs.
“All the link attributes — sponsored, UGC and nofollow — are treated as hints about which links to consider or exclude within Search. We’ll use these hints — along with other signals — as a way to better understand how to appropriately analyze and use links within our systems.” -Google, 2019.
Just. A. Hint. Which is all, from an engineering perspective, they ever would have been able to do, since “nofollow”‘s popularity got out of control over a decade ago.
So, do “nofollow” links have SEO value?
It seems to me that the answer is a clear, resounding yes.
Just as these links did last year. Only, on average, less. Be that 80 percent, half, or whatever model you want to go by. I think it’s reasonable to assume that it’s situational based on your tactics.
As we wrap up, let’s review the evidence.
- “nofollow” was originally supposed to take away all link value, but when we were told that, it was only for user-generated content. That didn’t last long at all, and now…
- “nofollow” now covers most of the web. Typically without any rhyme or reason (ie. Wikipedia). Do you believe that Google would willingly opt-out of most of the web’s link data for no gain? I don’t.
- Google’s increasingly vague language leading up to the 2019 announcement. “In general…,” “Won’t follow…,” “Won’t pass PageRank…” All these phrases dance around absolutes and a variety of other ranking variables.
- If you’re too lazy to run through the scientific method on this — to go get a high value “nofollow” link to yourself to confirm it — then let the studies linked above be your guide.
- Google penalizes manipulative backlink portfolios that demonstrate unusual patterns (for example, the Penguin Update’s 10 percent anchor text threshold). Ironically, if a brand sculpts all the “nofollow” links away, they’ve now got an actually manipulative-looking link footprint.
- And finally, our 2019 announcement (and subsequent Googler chatter) that “nofollow” is just a hint.